


What kind of data is actually needed to train healthcare algorithms? To build safe and effective models, developers require diverse, high-quality medical AI training data. This foundation primarily includes structured Electronic Health Records (EHRs), high-resolution medical imaging AI data (like MRIs and X-rays), and unstructured clinical notes. Furthermore, training requires complex genomic sequences and real-time biometric readings to construct a complete patient profile. To function safely in a real-world clinic, this information must be meticulously de-identified, accurately labeled by medical professionals, and representative of diverse populations. Without comprehensive clinical data for AI, systems simply cannot accurately diagnose diseases, predict patient risks, or recommend safe treatments.
Building artificial intelligence for the healthcare sector is vastly different from building consumer technology. The stakes are incredibly high, and the margin for algorithmic error is practically zero.
A machine learning model is essentially a blank slate; it only knows what it is taught. If you feed a system incomplete, outdated, or biased information, the resulting medical recommendations will be dangerous.
Understanding exactly what feeds these intelligent systems is critical for medical professionals, clinic managers, and health tech innovators. In this comprehensive guide, we will break down the specific data types required to build reliable healthcare infrastructure and why data quality ultimately defines patient safety.
The Foundation of Machine Learning in Healthcare

Before diving into the specific data types, it is important to understand how medical algorithms actually learn. AI does not "think" like a human doctor; instead, it relies on advanced pattern recognition.
To recognize these patterns, the AI requires a massive volume of historical data combined with a known outcome, often referred to as the "ground truth."
For example, to teach an algorithm to identify pneumonia, developers cannot just provide a textbook definition. They must feed the system tens of thousands of chest X-rays, explicitly telling the AI which images show pneumonia and which show healthy lungs.
Through this repetitive processing, the system eventually learns to identify the subtle pixel variations associated with the disease. Therefore, the depth, accuracy, and variety of the training data dictate the overall success of the final clinical tool.
The 4 Essential Healthcare AI Data Types
There is no single source of truth in medicine. A complete patient diagnosis requires looking at multiple distinct factors.
Similarly, robust clinical algorithms require a multi-faceted approach to data ingestion. Developers rely on four primary categories of data to train comprehensive medical systems.
1. Structured Clinical Data (EHRs and Vitals)
Structured data is the highly organized, easily searchable information found within a hospital's database. This is the numerical and categorized data that fits perfectly into spreadsheets and standardized forms.
This category includes vital signs (heart rate, blood pressure), demographic information (age, biological sex), laboratory test results, and standardized ICD-10 billing codes.
Because it is already organized, structured data is the easiest format for an algorithm to process. It is frequently used to train predictive models, such as systems that calculate a patient's risk for hospital readmission.
2. Medical Imaging AI Data
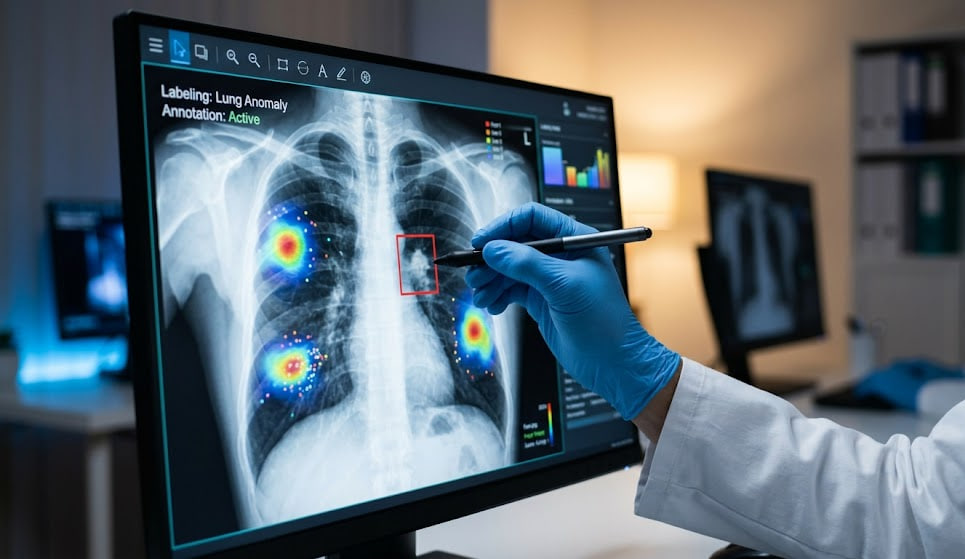
Radiology and pathology rely heavily on visual diagnostics, making medical imaging AI data one of the most critical components of modern algorithmic training.
This category includes X-rays, MRI scans, CT scans, ultrasounds, and digitized tissue slides. However, an AI cannot learn from a raw image alone.
These images must undergo a rigorous process called "annotation." Expert radiologists must manually review the scans and draw digital bounding boxes around tumors, fractures, or lesions. This painstaking human effort provides the ground truth the AI needs to learn.
3. Unstructured Text and Clinical Notes
It is estimated that up to 80% of valuable healthcare information is trapped in unstructured formats. This includes a doctor's free-text clinical notes, surgical reports, discharge summaries, and patient intake interviews.
Unlike structured numbers, free text is messy. It contains medical jargon, abbreviations, and subjective observations.
To utilize this data, developers use Natural Language Processing (NLP). NLP allows the AI to "read" and extract vital context from a physician's narrative, capturing nuanced symptoms that might not appear in a standard blood test.
4. Genomic and Wearable Device Data
The future of medicine is highly personalized, and AI training is evolving to include entirely new datasets. Genomic sequencing data provides a deep look into a patient's hereditary risks and cellular makeup.
Additionally, the rise of the Internet of Medical Things (IoMT) has introduced continuous data streams. Wearable devices, continuous glucose monitors, and smart telemetry beds provide real-time, longitudinal data.
By combining genomic profiles with continuous wearable data, AI models can be trained to deliver truly Personalized Patient Care, predicting health events before they physically manifest.
Are you looking to modernize your clinical workflows with secure, data-driven systems?
Managing the complex data required for modern healthcare does not have to be overwhelming. Explore our Advanced Diagnostics solutions to see how integrated technology can streamline your practice and improve patient outcomes.
The Crucial Role of Data Annotation and Expert Labeling
Having access to millions of patient records is useless if the AI does not know what it is looking at. Raw data must be transformed into labeled training data.
Data annotation is the highly specialized process of tagging medical data so a machine can understand it. In healthcare, this cannot be outsourced to standard data entry workers.
If an AI is being trained to detect diabetic retinopathy, an experienced ophthalmologist must manually review and label thousands of retinal images. They must highlight microaneurysms and hemorrhages pixel by pixel.
This requirement for expert human intervention makes building medical AI incredibly expensive and time-consuming. However, taking shortcuts in the annotation phase guarantees a flawed and unsafe algorithm.
Overcoming Algorithmic Bias Through Data Diversity

One of the greatest ethical challenges in healthcare technology is algorithmic bias. An AI model is a direct reflection of the demographic data it was trained on.
If a dermatology AI is trained exclusively on images of light-skinned patients, it will naturally struggle to identify skin cancer on darker skin tones. This leads to severe disparities in clinical care.
To build safe systems, developers must intentionally source diverse datasets. The clinical data for AI must accurately represent multiple ethnicities, age groups, genders, and socioeconomic backgrounds.
Organizations must actively audit their data pipelines to identify blind spots. Ensuring diversity in training data is not just an ethical obligation; it is a strict clinical necessity for patient safety.
Navigating Patient Privacy and Data De-Identification
Medical records are the most sensitive type of personal information in existence. Using this data to train software requires navigating a complex web of privacy laws.
Before any algorithm can look at a patient's file, the data must be scrubbed of Protected Health Information (PHI). This process is known as de-identification.
How Data is Safely De-Identified
- Direct Identifier Removal: Stripping out names, home addresses, phone numbers, and Social Security numbers.
- Date Masking: Shifting admission and discharge dates to obscure a patient's exact timeline while preserving the sequence of events.
- Text Scrubbing: Using NLP to find and redact patient names that a doctor may have accidentally typed into the middle of a clinical note.
Developers must strictly adhere to regulations like HIPAA in the United States or PIPEDA in Canada. Furthermore, modern frameworks often utilize "Federated Learning."
Federated learning allows an AI model to be trained directly within a hospital's local servers. The algorithm learns from the data, but the patient records never actually leave the hospital's secure firewall, drastically improving privacy.
For comprehensive guidelines on maintaining ethical standards while managing patient data, healthcare leaders should review the World Health Organization's guidelines on AI ethics.
How Data Quality Directly Impacts Clinical Outcomes
In the realm of artificial intelligence, there is a common saying: "Garbage in, garbage out." In healthcare, poor data quality translates directly to poor patient outcomes.
If an AI is trained on clinical notes filled with outdated medical practices, it will recommend outdated treatments. If it is trained on low-resolution, blurry X-rays, it will miss early-stage tumors.
Conversely, high-fidelity data creates powerful tools that empower doctors. When trained correctly, these systems act as an indefatigable second set of eyes, reducing human error caused by physician fatigue.
High-quality training data enables AI to flag subtle anomalies, cross-reference dangerous drug interactions instantly, and streamline the entire diagnostic process.
To ensure safety, regulatory bodies require developers to prove the origin and quality of their data. You can learn more about these stringent requirements by reviewing the FDA's regulatory framework for AI in healthcare.
Preparing Your Clinical Infrastructure for AI Integration
Understanding how algorithms are trained is the first step toward modernizing your medical facility. The next step is preparing your own infrastructure to utilize these intelligent systems securely.
Hospitals must move away from fragmented, siloed software. If your radiology department's imaging data cannot communicate with your EHR system, AI integration will fail.
Organizations must invest in interconnected platforms that prioritize data integrity and seamless interoperability. By upgrading your digital foundation today, you ensure your clinic is ready to deploy life-saving algorithms tomorrow.
Let’s Build the Future of Intelligent Healthcare Together Harnessing the power of medical data requires a secure, scalable, and fully compliant IT infrastructure. Whether you want to optimize your emergency department with Waitless ER or integrate intelligent systems across your entire clinic, we are here to help.
Contact InnoMed today to schedule a strategic consultation and take the next crucial step in your digital healthcare transformation.
Frequently Asked Questions (FAQ)
1. What is medical AI training data? Medical AI training data is the foundational information used to teach machine learning algorithms how to understand healthcare. It includes a vast collection of de-identified patient records, medical images (like MRIs), lab results, and clinical notes that help the AI learn to recognize diseases and predict health outcomes.
2. Why is medical imaging AI data so difficult to prepare? Medical imaging is difficult to prepare because raw images are useless to an untrained AI. Every image must be meticulously reviewed and annotated by specialized human doctors (like radiologists) who manually highlight tumors, fractures, or anomalies so the algorithm has an accurate "ground truth" to learn from.
3. What is algorithmic bias in healthcare AI? Algorithmic bias occurs when an AI system performs poorly for certain demographics because it was not trained on diverse data. For example, if an algorithm is only trained on data from younger patients, it may provide inaccurate or dangerous diagnostic recommendations when used on elderly patients.
4. How is patient privacy protected when training medical AI? Patient privacy is protected through strict de-identification processes. Before an AI algorithm analyzes any records, all Protected Health Information (PHI)—such as names, addresses, specific dates, and identification numbers—is completely stripped or masked to ensure the data cannot be traced back to an individual.
5. Can unstructured clinical data for AI be used for training? Yes. Unstructured data, such as a doctor's free-text notes or surgical summaries, contains incredibly valuable insights. Developers use Natural Language Processing (NLP) technology to help the AI "read" these notes, extracting key symptoms and context that are not captured in standardized numeric forms.




